In this post we describe the design of a test scenario for running Jmeter load tests against a MySQL database. We also show an example of how new data records can be generated from pre-existing records in the database in Jmeter, thereby giving you a larger test database to work with.
The Apache JMeter application is open source software designed to load test functional behavior and measure performance. It was originally designed for testing Web Applications but has since expanded to other test functions, including MySQL databases. In this article we will describe the design of a one such test scenario. The test described below could help you design your own test scenarios that closely mimic your application and production database usage.
Pre-requisites
If you are new to Jmeter and need help getting started, we recommend the excellent introductory Jmeter tutorial from Blazemeter. We assume you have access to a Jmeter installation with the MySQL JDBC plugin already installed; further, if you want to run the test, you will need to point the Jmeter test to a MySQL database instance; if you don’t have a test MySQL box then an easy way to get a test MySQL instance on your local machine is by using a MySQL docker container. Please don’t use your production MySQL server for testing!
The Scenario
We will use a standard test database called “employees”. The Employees sample database was developed by Patrick Crews and Giuseppe Maxia and provides a combination of a large base of data (approximately 160MB) spread over six separate tables and consisting of 4 million records in total. You can follow the instructions for downloading and using the employees database. The entity relationship diagram for the database is reproduced in Fig.1 below.
Fig.1: Employee Database Schema
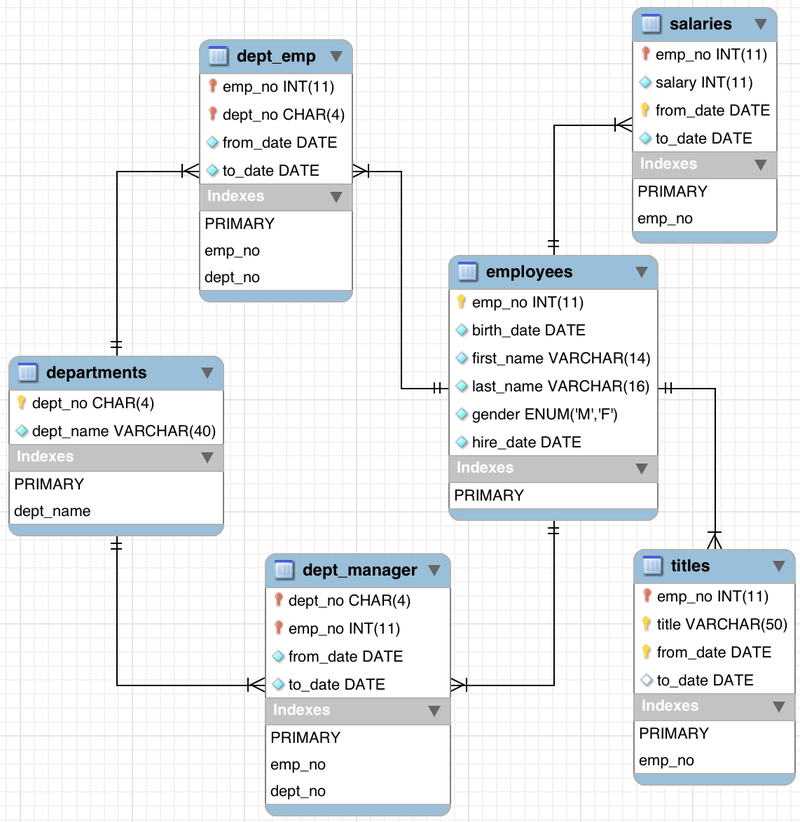
Our aim is to start with this initial database and perform a number of read and write operations on the database using Jmeter.
For this test scenario we will read records at random from the database, “mix” information obtained from these random records in Jmeter to create “new” records, and then write back these newly created records to the database. This exercises the database for both reads and writes.
Constructing the Scenario
We will now start constructing the Jmeter test file (a “jmx” file). This is best done through the Jmeter GUI; If you need help with setting up the JDBC connection settings in Jmeter to connect it to your MySQL database then please read this article.
Lets enumerate the steps we want Jmeter to perform to create a new record in our database based on our scenario above. We will use a Jmeter JDBC request sampler for each SQL statement and a Jmeter random variable config element to generate random data in the steps below.
Reading and Generating Random Data
- Read two random employees from the database; we’ll use these 2 records later to “mix” the information fields of the two employee records to create a “new” employee.
SELECT last_name, first_name, gender, hire_date, birth_date FROM employees WHERE RAND() < 0.0001 LIMIT 0,2;Fig.3: Read 2 random employee records
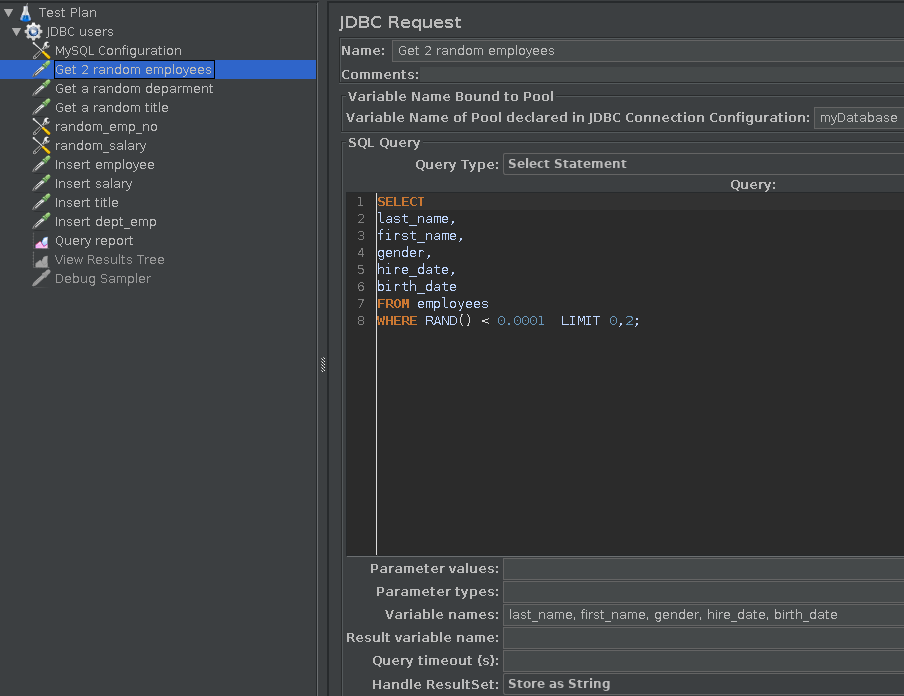
We insert this query via the Jmeter GUI as shown in Fig.3. Look at the field titled “Variable names” toward the bottom of the picture. These variables become available to us to use in the INSERT queries later. This is the key to re-using Jmeter SELECT query results in INSERT queries.
Notice the additional entries in the form - the pool variable (“myDatabase”) and the query type (SELECT statement).
-
Find a random department where this “new” employee will work.
SELECT dept_no FROM departments ORDER BY RAND() LIMIT 0,1;Fig.4: Read a random department record
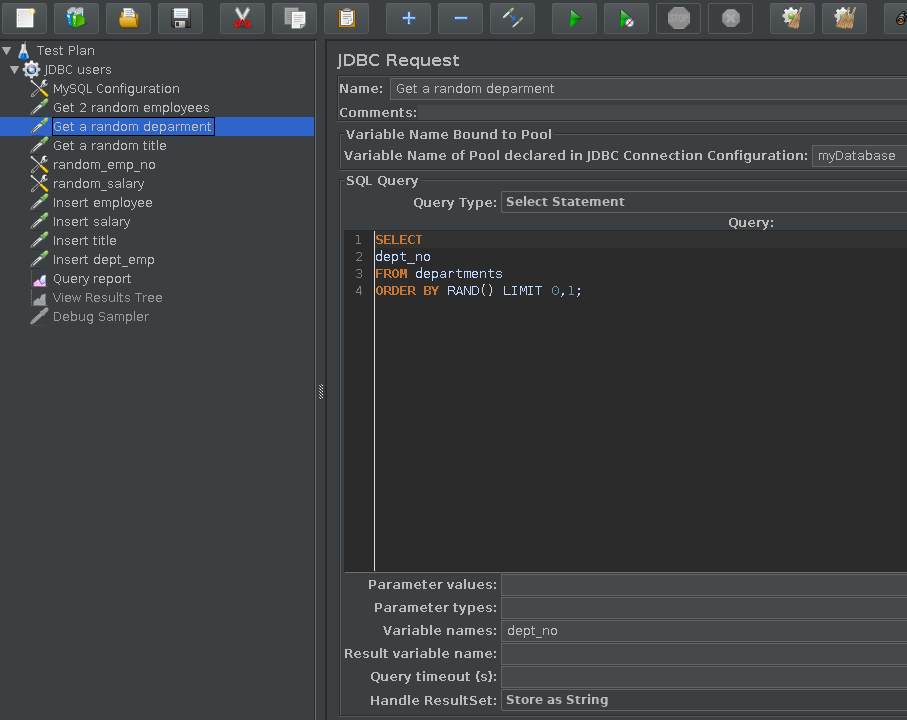
Again, we add “dept_no” in the variable name field in Fig.4.
-
Get a random title from among all the titles in the database (Fig.4).
SELECT title, from_date, to_date FROM titles WHERE RAND() < 0.0001 LIMIT 0,2;Fig.5: Read a random title record
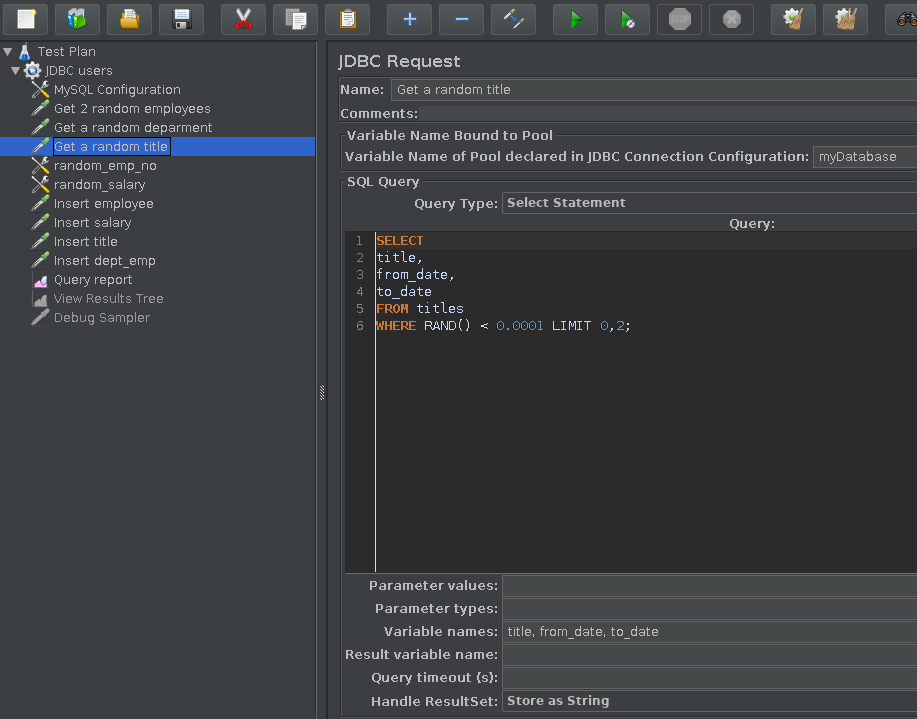
We add “title”,”from_date” and “to_date” to the Variable names’ field as shown in Fig.5.
- Generate a “random” employee number. This is an integer; we simply tell Jmeter to create a random number between 10m and 1B, as illustrated in Fig.6’s screenshot.
Fig.6: Generate random employee number
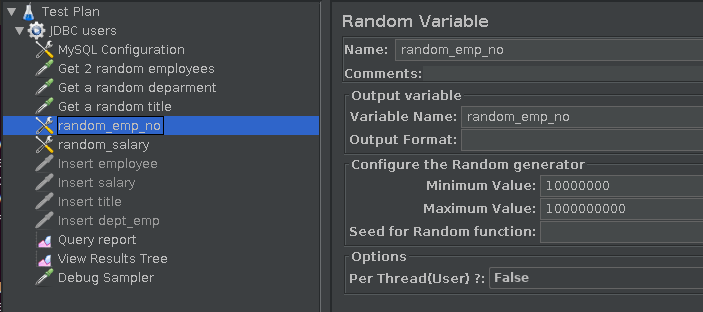
This random number generation will eventually generate a few collisions (duplicate employee numbers); for our use case thats fine, we let the database deal with this error.
-
Similarly, generate a random salary as shown in Fig.7; here we have chosen that the salary is between 25,000 and 300,000.
Fig.7: Generate a random salary
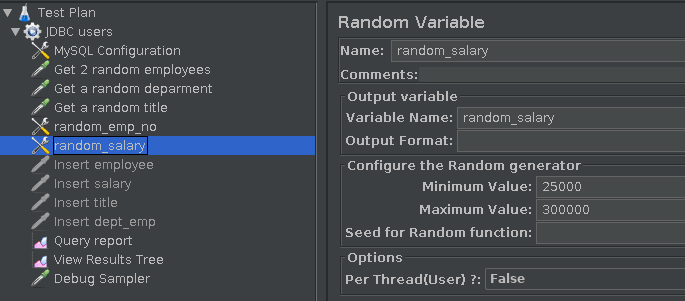
Writing New Data to the Database
The next steps are to use the data gleaned from steps 1..5 above to create SQL insert queries.
We have now read the data off the database and generated some random data. We saved the data into variables that we can now use. Fig.8 shows a screenshot of the “View Results Tree/Debug Sampler” after we run a single loop of the steps above (we added the View results tree sampler and the Debug sampler to see this output; for performance reasons please disable the debug sampler when you run your actual multi-loop/thread test).
Fig.8: Variables available to create INSERT statements
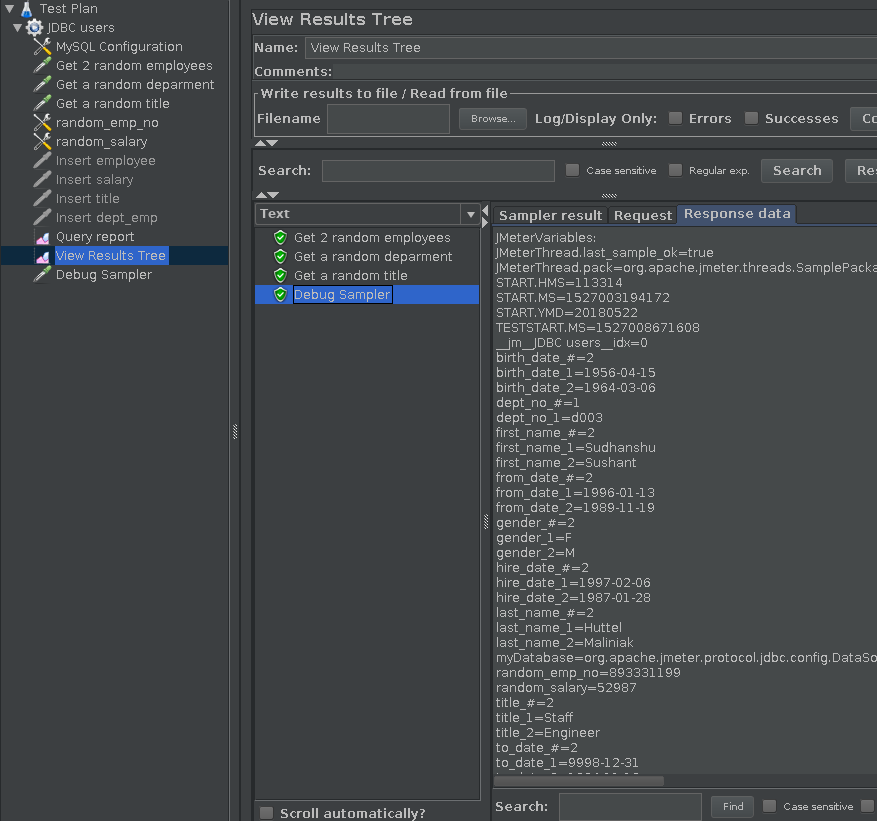
We create SQL INSERT statements to create the records (1 JDBC request sampler per SQL statement below).
-
Create a new employee record.
INSERT INTO employees (emp_no, birth_date, first_name, last_name, gender, hire_date) VALUES (${random_emp_no}, STR_TO_DATE('${birth_date_2}','%Y-%m-%d'), '${first_name_2}', '${last_name_1}', '${gender_2}', STR_TO_DATE('${hire_date_1}','%Y-%m-%d'))Notice how we mixed the first name of the second record and the second name of the first record. Similar techniques are used in the remaining steps below. Notice in Fig.9 that the query type is set to “Update statement” to correspond to a database INSERT.
Fig.9: INSERT statement to create new employee record.
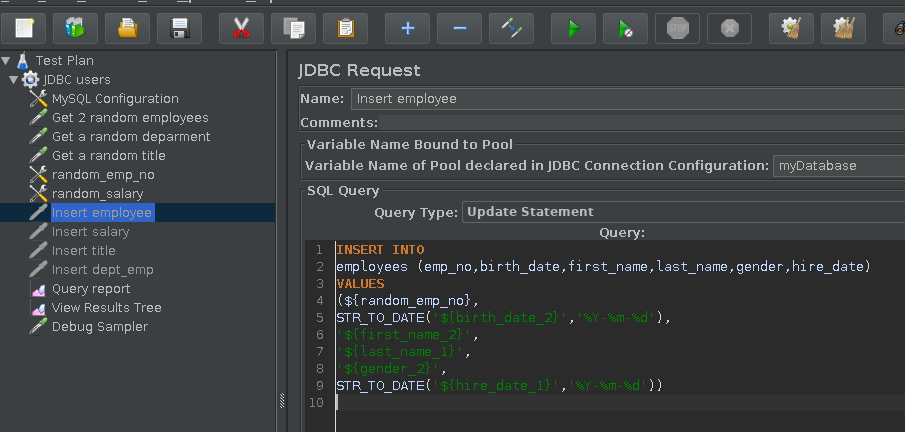
-
Add a new salary (and use the same random employee number as used in step 6 above).
INSERT INTO salaries (emp_no,salary,from_date,to_date) VALUES (${random_emp_no}, ${random_salary}, STR_TO_DATE('${hire_date_1}','%Y-%m-%d'), STR_TO_DATE('${to_date_2}','%Y-%m-%d')) -
Add a title.
INSERT INTO titles (emp_no,title,from_date,to_date) VALUES (${random_emp_no}, '${title_2}', STR_TO_DATE('${hire_date_1}','%Y-%m-%d'), STR_TO_DATE('${to_date_2}','%Y-%m-%d')) -
Add the record into the department-employee mapping table.
INSERT INTO dept_emp (emp_no,dept_no,from_date,to_date) VALUES (${random_emp_no}, '${dept_no_1}', STR_TO_DATE('${hire_date_1}','%Y-%m-%d'), STR_TO_DATE('${to_date_2}','%Y-%m-%d'))
Jmeter File
The final version of the Jmeter jmx test file created in the above steps can be downloaded from here. Remember that the file contains the database connection strings (username and password) in plaintext; so do not put your own copy with those credentials online unless you carefully redact those entries.
Outlook
We have demonstrated a very powerful Jmeter technique of using data from earlier samplers in subsequent samplers - we used earlier samplers to read from the database and used later samplers to use the data read to create new data to insert into the database. The JMX file we generated can be run with multiple loops/threads to load up a database.
This example is a write heavy workload and may not mirror real-world usage of your application; additionally you could optimize the SELECT statements while choosing random records from the database. Our example should give you the tools to get started with generating almost infinite new data to use for your test cases.
*
Sachin Agarwal is a computer systems researcher and the founder of BigBitBus.
BigBitBus is on a mission to bring greater transparency in public cloud and managed big data and analytics services.